Half a year ago, I got this crazy idea to build a site where people could log and record all the things they wanted to accomplish before they died. But more than just simple list-making, I wanted to make it easy for people to tell stories about their goals, and to add images and video. I wanted to let people “follow” other people’s lists, to receive email when their friends accomplished their goals, to start discussions about getting the most out of life. I wanted it to be a place where people could get inspired by the goals of others, and to easily make copies of those goals in their own bucketlists.
I had a pre-existing love affair with the Python-based Django framework – there was never a question of what platform to build on. But no matter how good the platform, the devil’s in the details. Continue reading “Building a Bucketlist Site with Django”
Building a site that needs to accept formatted user input? There’s no way you’re going to let random users input any old HTML – you’d open the door to all kinds of cross-site-scripting attacks and other nastiness. Nor can you just filter out the tags you consider dangerous – that road is fraught with peril. The only solution is to white-list a small subset of tags and unceremoniously drop the rest.
There are two layers to the problem – how to support formatted text on the front-end, and how to process submitted text on the back-end.
For the front-end, some developers are drawn to the Markdown syntax – a supposedly user-friendly wiki-like syntax that can be re-rendered as safe HTML. But while Markdown may look friendly to developers, it doesn’t to normal users – trust me on this. Even for tech-savvy users, Markdown requires that you place syntax instructions on your site (inelegant). A better solution is to use a rich text editor for the web, like TinyMCE or WYMEditor.
Ever notice that you often see rich text editors in content management systems run by trusted users, but seldom on public-facing web pages? That’s because it’s tricky to do securely, and without giving users enough rope to hang themselves formatting-wise.
With a bit of configuration though, you can deploy public-facing rich textareas securely, allowing only the input of tags you specify. But you can’t stop there – all the user has to do is disable Javascript in the browser to bypass your rich text editor. You must process submitted text on the back-end with the same set of rules in your view logic.
There’s a large body of technical information out there about content management systems and frameworks, but not much written specifically for decision-makers. Programmers will always have preferences, but it’s the product managers and supervisors of the world who often make the final decision about what platform on which to deploy a sophisticated site. That’s tricky, because web platform decisions are more-or-less final — it’s very, very hard to change out the platform once the wheels are in motion. Meanwhile, the decision will ultimately be based on highly technical factors, while managers are often not highly technical people.
This document aims to lay out what I see as being the pros and cons of two popular web publishing platforms: The PHP-based Drupal content management system (CMS) and the Python-based Django framework. It’s impossible to discuss systems like these in a non-technical way. However, I’ve tried to lay out the main points in straightforward language, with an eye toward helping supervisors make an informed choice.
This document could have covered any of the 600+ systems listed at cmsmatrix.org. We cover only Drupal and Django in this document because those systems are highest on the radar at our organization. It simply would not be possible to cover every system out there. In a sense, this document is as much about making a decision between using a framework or using a content management system as it is between specific platforms. In a sense, the discussion about Drupal and Django below can be seen as a stand-in for that larger discussion.
Disclosure: The author is a Django developer, not a Drupal developer. I’ve tried to provide as even-handed an assessment as possible, though bias may show through. I will update this document with additional information from the Drupal community as it becomes available.
I recently got to work on an interesting Django side project: the Bay News Network – a directory of Bay Area bloggers and hyperlocal news sites. The goal of the site was three-fold:
To create a many-to-many directory of local sites that matched our editorial criteria
To let site owners log in and edit their own listings
To both consume and produce RSS feeds from the listed sites
The first two were pretty standard Django approaches – develop data models and editing interfaces using Django forms and re-usable apps like django-profiles and django-registration. The third goal turned out to be more interesting. We not only had to gather RSS feeds from more than 100 external sites several times per day, we needed to re-mix them (e.g. provide an integrated feed representing all blogs that cover Food, or all blogs that cover Oakland).
“Consuming” RSS feeds meant we needed to integrate feeds from the external sites into our own site. At the most basic level, this was pretty straightforward using Mark Pilgrim’s excellent Universal Feed Parser, which turns the real-world’s tag soup of disparate, incompatible RSS formats into a reliable data format you can step through in your code or templates. This worked well enough until I realized that grabbing and parsing external feeds in real-time was just not going to scale, performance-wise. Plus, we still had the RSS mashups to build, and would clearly need to be storing feed entries in our own database in order to sort them by category, etc.
Thus began the hunt for good feed aggregation systems for Django. Most roads pointed to django-planet, planet planet, and FeedJack, which are systems for gathering content from external sites and importing it into a single aggregated site. These were close to what I wanted, but weren’t great on the re-usability side. Since I already had existing models to define the sites, their owners, and their feeds, I didn’t want to rewrite all my models to work with another system’s conception of how things should be laid out. I also didn’t feel like plowing through their source code to chop out and rewrite just the bits I wanted. Eventually realized that I was looking for a few lines of code to work with my system, not a whole external system.
The surprising solution came from the Community section of the official Django project web site. The Django developers keep the code that drives djangoproject.com in subversion along with the source code to Django itself. And the code that drives that section of the site is really lightweight. So I did a subversion checkout of the Aggregator app, and found that all I really needed from it was its update_feeds.py script, which itself is a wrapper around Universal Feed Parser, tweaked to talk to my own models.
Two gotchas to be aware of:
The app includes a bundled templatetags directory with a file called aggregator.py. But the name of the app itself is “aggregator.” I was getting strange import errors in various places before I discovered on the django-users mailing list that Django doesn’t like it when an app name matches a templatetag name. Easily fixed by renaming the templatetag.
My first runs of update_feeds.py went fine, but later started erroring out with database integrity errors. The GUID field on the FeedItem model is set to unique=True, which prevents your database from storing any one FeedItem more than once. That’s great, but it was dishing up integrity errors for some reason. I fixed this by changing this line in update_feeds.py:
feed.feeditem_set.get(guid=guid)
to:
FeedItem.objects.get(guid=guid)
Once I was able to get the updater to run consistently without error, I needed to get it running via cron. The trick to running a Python script that talks to the Django ORM from a crontab is that you must supply the full Python paths in the environment to cron – it doesn’t pick them up automatically from the environment of the user that runs the cron job. This worked for me:
With the harvesting system up and running, and all content coming into the datbase associated with blogs that were in turn categorized by “beat” and geographical area, outputting aggregated RSS feeds was a simple matter of using Django’s native syndication framework as documented. This went into urls.py:
… and I created a file feedgenerator.py to contain the three corresponding classes and their querysets, using Holovaty’s sample code from chicagocrime.org as a starting point.
Apparently I’m not the only one having trouble getting MySQL and Python to play nice under OS X — last February’s post on getting the two to cooperate under OS X has generated a ton of traffic. Now I’ve upgraded to Snow Leopard and faced a handful of new challenges (but eventually got it working). Rather than scatter my notes, I’ve updated the original post with Snow Leopard instructions.
The User model in Django is intentionally basic, defining only the username, first and last name, password and email address. It’s intended more for authentication than for handling user profiles. To create an extended user model you’ll need to define a custom class with a ForeignKey to User, then tell your project which model defines the Profile class. In your settings, use something like:
The Knight Digital Media Center, which runs on Django, hosts week-long workshops for working journalists who come from around the country to learn multimedia and internet technology skills. We fill many of our lunch and dinner sessions with talks by journalism industry experts and pundits, and webcast their presentations live. After workshops are over, we post the archived video for posterity. There’s more to handling multi-day, multi-part live and archived video with Django and a genuine streaming server than meets the eye, so thought I’d break it down.
An “event” can last any number of days, and can include any number of presentations, each of which may or may not include a webcast. While the event is in progress, you want the ability to advertise a single URL, where all of the live webcasts will happen. But for the archives, which is where the vast majority of viewing happens over the course of time, you want a separate page/URL for each presentation. Presentation pages include details on that speaker, summaries of what was presented, and optional downloads of PowerPoint or Keynote presentations. Our Presentation model is foreign-keyed to a master Event model (or, in our case, the Workshop model).
Because they’re time-based, synchronous events, webcasts are different from typical web pages. There are five possible “states” a webcast page can be in at any given time, all of which require different things to be inserted into the view:
Upcoming: The event is announced but there’s nothing yet to show. Tell user that webcast will be live at posted time (along with schedule).
In progress: The event is occurring. Insert appropriate object code to embed live QuickTime stream.
Concluded: The live webcast has ended, but the archives haven’t yet been prepared and posted (this can take us a few days). Tell user to come back soon.
Archive: The archived video is prepared and available on the streaming server for posterity. Insert appropriate object code to display streamed archive file from QuickTime Streaming Server.
External: We sometimes host events at other locations on campus, in which case UC Berkeley handles the webcasting rather than us. If so, we need to link from our events database to theirs. Insert appropriate message and link.
In Django, we represent these choices with the typical CHOICES construct:
… which ends up looking like this in the Django admin:
Depending on the current state, different content (text or object/embed code) is inserted into the page in real time (using simple conditionals in Django templates). The Django admin thus becomes a handy tool our student helpers can use to make the master workshop page embed the right thing in the right place at the right time without requiring tech skills. Remember, during the course of a workshop week, all video is happening in the master Workshop page – later, streaming video archives will go into separate Presentation pages and be automatically linked to from the parent Workshop page.
Stream Handles
At the J-School, we use QuickTime Streaming Server, in part because it’s free, and in part because all of our workstations and most of our servers are Macs. We’ve contemplated switching to Flash streaming, but the simplicity of keeping everything Mac-native keeps us on QTSS for now.
Embedding a stream from an external QTSS server is not quite as straightforward as embedding a typical QuickTime movie. Video comes from QTSS over the rtsp:// protocol, rather than http://. And there’s the catch: You can’t embed an rtsp stream directly into a web page — instead, you need to embed a fake QuickTime movie (a “reference movie”), which is actually a text file with the .mov extension. That text file simply references the full URL of the rtsp stream coming from QTSS. The contents of a reference movie file might look like this:
Here’s where things get interesting as far as Django is concerned. We don’t want to have to create a physical reference movie for every single stream we serve. And yet, at the HTML level, we have to embed something that looks like a reference to a physically external movie file, e.g.:
So how can we make Django think that /presentations/webcast-archive.227.ref.mov is an actual file on the server, which in turn contains the correct reference to the rtsp stream coming from the streaming server? In effect, it’s a “view within a view.”
Click for larger version
Displaying the presentation page is straightforward Django – I won’t get into that here. But here’s how the “view within a view” stuff works. In the object section of the presentation page template there is a reference to:
which resolves to something like:
When the browser hits that line, it requests /presentations/webcast-archive.267.ref.mov from the server, which in turn triggers this entry in urls.py:
So after the presentation page has been rendered by Django and sent to the browser, a second (very simple) view, presentation_webcast_archive, is called, which is simply:
def presentation_webcast_archive(request, pres_id):
"""
Generate a virtual QuickTime reference movie on the fly,
to be embedded in presentation webcast pages.
"""
pres = get_object_or_404(Presentation,id=pres_id)
return render_to_response( 'workshops/presentation_webcast_archive.txt',
{
'p': pres,
}, context_instance=RequestContext(request),
)
That view spits out the same presentation object to a different template, presentation_webcast_archive.txt, which consists of:
Where webcast_path and webcast_filename are fields on the model representing the physical location of the QuickTime media on the streaming server (not the web server). After a workshop week is over, staff only need to hint the saved archive files, upload them to a directory and filename on the streaming server, enter those paths in the Django admin, and check the “Has Webcast” box. The rest is automatic.
In a previous, PHP-based version of this system, we had to prepare an actual reference movie for every archive stream we hosted. By using this “view within a view” technique, Django has let us remove that part of the workflow.
In all of Mac-dom, there are few experiences more painful than trying to get Python tools to talk to a MySQL database. Installing MySQL itself is easy enough – Sun provides a binary package installer. Python 2.5 comes with Mac OS X. If you enable Apache and PHP, your PHP scripts will talk to your installed MySQL databases just fine, since PHP comes bundled with a MySQL database connector. But try to get up and running with Django, TurboGears, or any other Python package where MySQL database access could be useful (or needed), and you’re in for a world of hurt.
Update: I finally did manage to get Python and MySQL playing nice together, but it took a few more contortions beyond what’s described in the recipes found scattered around the interwebs. I’ve added my solution at the end of this post.
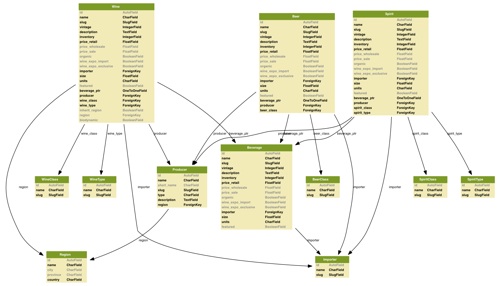
I’ve been watching the django-command-extensions project out of the corner of my eye for a while, promising to give it a shot. With the extensions added to your installed_apps, manage.py grows a bunch of additional functionality, such as the ability to empty entire databases, run periodical maintenance jobs, generate a URL map, get user/session data… and to generate graphical visualizations from models.
A recent post by John Tynan on the power of command extensions finally kicked my butt enough to give it a spin. Essential stuff for debug and development work.
Getting visual graphing to work takes a bit of extra elbow grease, since it depends on a working installation of the open graphviz utilities as well as a Python adapter for graphviz, PyGraphviz. graphviz itself has both command-line utilities (which I got via macports) and a GUI app for opening and manipulating the .dot files that graphviz generates.
Took some wringing of hands and gnashing of teeth to get macports to happily install all of the pieces, but finally ended up with this:
The key to getting decent resolution output, I found, is to output a graphviz .dot file rather than PNG. You can’t control the relatively low resolution of the latter, but .dot files are vector, and can be exported from the GUI Graphviz app to any format, including PDF (infinite resolution!).
Amazing to be able to visualize your models like this, but it’s not perfect. What you don’t see reflected here is the fact that Wine, Beer, etc. are actually subclassed from the Beverage model. And the arrows don’t even try to point to the actual fields that form table relations, which would be nice. graph_models has a way go, but it’s still a terrific visualization tool for sharing back-end work with clients in a way that makes immediate sense.
Earlier this year, I inherited responsibility for the website of the Knight Digital Media Center at UC Berkeley’s Graduate School of Journalism. The site is built with Django, a web application framework written in Python. The J-School has primarily been a PHP shop, using a mixture of open-source apps — lots of WordPress, Smarty templates and piles of home-brew code. Because it’s grown organically over time with no clear underlying architecture and a constantly changing array of publications to support, the organization sits on top of dozens of unrelated databases.
These are my notes and observations on how the J-School got into this mess, why we’ve fallen in love with Django, and how we plan to dig ourselves out.



 There’s a large body of technical information out there about content management systems and frameworks, but not much written specifically for decision-makers. Programmers will always have preferences, but it’s the product managers and supervisors of the world who often make the final decision about what platform on which to deploy a sophisticated site. That’s tricky, because web platform decisions are more-or-less final — it’s very, very hard to change out the platform once the wheels are in motion. Meanwhile, the decision will ultimately be based on highly technical factors, while managers are often not highly technical people.
There’s a large body of technical information out there about content management systems and frameworks, but not much written specifically for decision-makers. Programmers will always have preferences, but it’s the product managers and supervisors of the world who often make the final decision about what platform on which to deploy a sophisticated site. That’s tricky, because web platform decisions are more-or-less final — it’s very, very hard to change out the platform once the wheels are in motion. Meanwhile, the decision will ultimately be based on highly technical factors, while managers are often not highly technical people.